Our paper about adaptive target normalization in deep learning was accepted at NIPS 2016. A preprint can be found on arXiv.org. The abstract and a more informal summary can be found below.
Update: There are now videos of the effect of the new approach on Atari.
Abstract
Most learning algorithms are not invariant to the scale of the function that is being approximated. We propose to adaptively normalize the targets used in learning. This is useful in value-based reinforcement learning, where the magnitude of appropriate value approximations can change over time when we update the policy of behavior. Our main motivation is prior work on learning to play Atari games, where the rewards were all clipped to a predetermined range. This clipping facilitates learning across many different games with a single learning algorithm, but a clipped reward function can result in qualitatively different behavior. Using the adaptive normalization we can remove this domain-specific heuristic without diminishing overall performance.
Summary
Sometimes we want to learn a function for which we don’t know the scale beforehand, or where the scale can change over time. For instance, in value-based reinforcement learning the target values can repeatedly change when our policy improves. In the beginning these values might be small, because our policy is not yet great, but over time their magnitude might increase repeatedly and unpredictably. This is a problem for many optimization algorithms used in deep learning, because they were often not developed with such cases in mind and can be slow or unstable in practice.
For instance, consider learning to play Atari games. First the scores are low because the policy is poor while later the incoming rewards may become much higher. Furthermore, the feasible scores can greatly differ for different games but ideally we want one system that can play all games, without having to retune hyperparameters such as the learning rate for each game separately.
The original DQN paper, and many later improvements, avoided these issues by clipping all incoming rewards to -1 and 1. However, this changes the problem we are asking the agent to solve. For instance, eating a ghost in Ms. Pac-Man then seems to give the same reward as eating a measly pellet.
We propose to instead adaptively normalize the targets we present to the deep neural network. We show a naive target normalization could make learning very non-stationary, because all the outputs of the network would change each time we update the normalization, even for inputs where the network was already accurate. Therefore, our algorithm makes sure to preserve all outputs precisely whenever it updates the normalization. We call the resulting method Pop-Art, an acronym for preserving outputs precisely while adaptively rescaling targets.
To get a feel for the effectiveness of this method, we can look the norms of the gradients during learning across 57 Atari games. This gives the following picture:
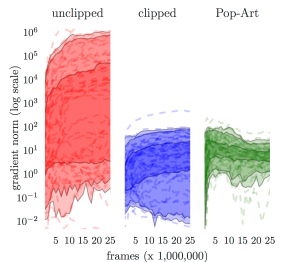
Unclipped Double DQN is shown on the left, the clipped version is in the middle, and the version with Pop-Art is on the right. Each dotted line represents one game and the shaded regions represent (50%, 90%, and 95%) percentiles across games. In other words, the norms of the gradients of approximately half the games fall in the darkest shaded region in all three plots. Clearly, the use of Pop-Art results in much more consistent gradients, whose norms fall into a much narrower, and therefore more predictable, range. The unclipped version is much more erratic – note the log scale on the y-axis. Pop-Art even has better-normalized gradients than the clipped variant, without qualitatively changing the task as the clipping does.
This follow-up post includes some videos that show how the learned behavior of the clipped agent differs from the behavior of the agent that instead uses Pop-Art.

Reblogged this on Do not stop thinking.
LikeLike