Today Ziyu Wang will present our paper on dueling network architectures for deep reinforcement learning at the international conference for machine learning (ICML) in New York. This paper received the best paper award.
The elegant main idea of the paper is to separate the value of a state and the advantage value for each action in that state. Concretely, the action values Q(s,a) can be written as the sum of a state-dependent offset V(s) and the advantage A(s,a) for specifically taking action a in that state, such that:
Q(s,a) = V(s) + A(s,a)
This action value is represented with a network architecture that features two streams. One stream represents the state value and the other the advantages. These streams are then merged to obtain an estimated action value. Graphically, the difference between the conventional DQN network and this new network looks like this:
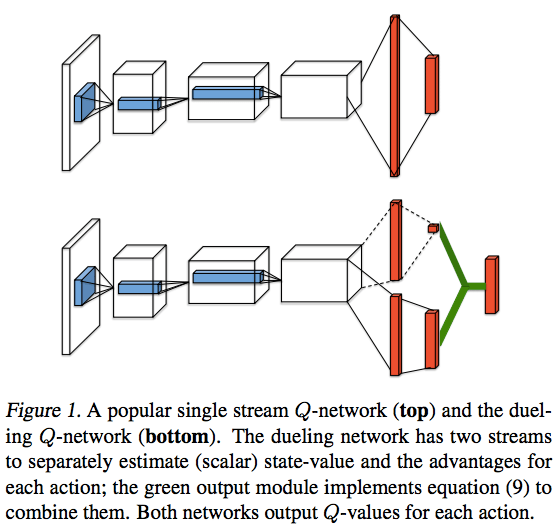
In the paper, we combine this innovation with Double DQN and prioritized experience replay and the resulting algorithm obtains state of the art results on the Atari 2600 benchmark.

One Comment Add yours